NeurIPS - Ariel Data Challenge 2025 回顾

前言
参加了于2025年6月27日〜2025年9月25日举办的NeurIPS - Ariel Data Challenge 2025[1],并于1038名参赛者和860个队伍中取得了第七名,与我的第一块金牌。这次还在中盘之后与同为kaggler的takaitoさん组队了,这次solo的话,取得金牌可能非常困难,因此非常感谢takaitoさん在的一起讨论和努力! 我在Icecube比赛的时候就follow了takaitoさん,可以说是我最早记住的kaggler之一,因此非常高兴这次能够一起组队。
我们队伍的解法已经发表于kaggle上,详细解法与技术相关请移步:7st Place Solution。
本记事将不集中于技术,而是我对于比赛的回顾和感想。
在参加ADC2025之前我实际上正在打NeurIPS - Open Polymer Prediction 2025,但由于其严重的数据泄露,我决定放弃这个比赛,后来事实证明我是正确的,因为Open Polymer Prediction已经完全失去了其科学价值。
概要
截至目前,我们已知的系外行星超过5600颗。探测这些行星是第一步;然而,发现行星只是第一步。理解它们的本质,尤其是其大气成分,才是揭示“另一颗地球”可能性的关键。2029年,欧空局阿里尔任务将对我们银河系附近的1000颗系外行星进行首次全面研究。因此本次比赛以 ESA(欧洲空间局)的 Ariel 太空望远镜为背景,模拟系外行星凌日(Transit)过程中的光谱观测任务。
当系外行星正好从我们视角穿过其主恒星前方时,就会发生所谓的“凌日(Transit)”现象,如图所示。
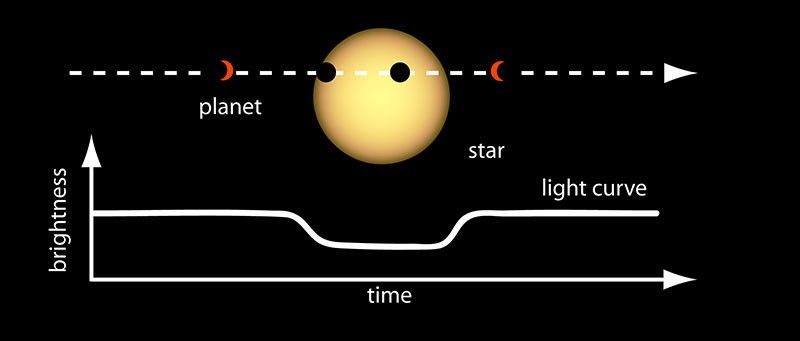
Figure1 凌日示意图[2]
此时,恒星的亮度会出现轻微但可测的下降,一部分星光被行星本体遮挡,更小一部分星光穿过了行星稀薄的大气层,与其中的气体分子(如 H₂O, CO₂, CH₄ 等)发生吸收与散射,导致在某些特定波长 λ上的亮度下降得更多。
这种波长依赖的凌日深度$\delta(\lambda)$,就形成了所谓的“凌日光谱(Transmission Spectrum)”,携带着行星大气的化学组成信息。
同时,凌日深度又可以利用$\left( \frac{R_p(\lambda)}{R_s} \right)^2$估算,因此也可以理解为预测行星与恒星的半径在不同波长下的比例。
因此,我们需要预测283个波长下的不同凌日深度$\delta(\lambda)$(wl_pred)和其对应的不确定度sigma $\sigma(\lambda)$(sigma_pred),也就是说,每个样本有 566 个 target(283 × 2),分别代表不同波段下的物理信号强度与置信度。同时,比赛使用Gaussian Log-likelihood (GLL) function,这是一个极度敏感的指标,sigma的轻微变化就会导致分数出现天差地别。对模型输出的置信度表达能力提出了极高要求。
前期
ADC2025是ADC2024年的强化版,尽管有的kaggler认为应该“forget everything you know about ADC2024.”,我仍然非常细致的重读和吸取了2024年的经验。在前期阶段,我主要集中于结合和重构ADC2024的top方案,并很快来到了金段。
在大约7月19日的时候,数据进行了一次更新,由于原始的数据没有考虑行星轨道周期的问题,导致了不合理的凌日时间。而这次更新也使得数据难度进一步增加,数据中出现了异常样本,这些样本用于过长的凌日时间,导致完全观测不到非凌日段。在进行了大量的修复后仍然维持在了金段。
多亏了这一部分的修复bug,让我对于数据有了更深的感受。我在解决方案中所写的使用低阶多项式的idea也正是来源于这一阶段。我认为这对于提升了我们方法在private test set三上的稳定性非常关键。
中期
takaitoさん很快在中期也突入了金段,虽然我本打算solo达到0.5后再进行队伍合并,但因为逐渐感觉到了来自包括エチレンさん和JFPuget+Dieter的压力,而且takaitoさん在2024年取得了15名,使用了一套以NN为主的方案,我相信他的经验和不同的方案能带来巨大的探索空间,因此我决定和takaitoさん先取得联络。 而当最高分数出现了0.596后,我们决定进行队伍合并。
takaitoさん,基于去年的深度学习方案进行构筑和优化,比起我详细的构建了物理模型和稳定的基准wl_pred,他则是使用了极为简单的物理方法作为基准,并集中优化NN模型。这和我深挖的部分完美互补,在将我的方法和他的方法结合后,我们的分数非常顺利的大幅提升并进入0.5。
由于我原本的方案主要集中在优化正向建模和简单的后处理(PLS等),takaitoさん的加入直接让我得以抛弃原本过于粗略的后处理,而使用我之前没能成功应用的NN部分,更加有效的利用了由我的物理建模带来的特征和信息,感到非常的感谢。sigma的矫正步骤,也是在这一阶段,基于takaitoさん带来的方法得以有效的提升。
后期
后期的压力逐渐上升,我们没能再回到赏金圈,虽然我尝试从数据预处理等部分寻找大幅度提升分数的magic,但最终还是失败了,参考2024年的magic,尝试了对预处理的各种微调但对最终的结果完全没有影响。这一点很不甘心。而我和takaitoさん也一直猜测着至少包括2只队伍可能会在最终阶段突然飞到金段,因此我们开始采取稳步提升分数的策略,小幅调整每一个模型。考虑到时间,我甚至在这一阶段用上了两张A100,以尽可能的增加可以并行的实验数量。
最后两天几乎没怎么睡觉,为了充分利用最后的所有提交,都是直到日本时间早上9点左右才睡下。
最终日的夜晚,我们调整着最后的pipline。我们的实装一直有着各种小的bug。导致最后直到日本时间26:00才完成所有提交。我们为了防止最终提交不能及时完成,takaitoさん不得不妥协的减少了Pseudo Labeling的计算量,为自己的失误感到非常抱歉。
而最终提交确实也是勉强赶上,但最高分却超时了8分钟。
结语
最后坐立不安的等到了早上,shake之后得到了7位。我觉得我最大的失误是在最后一晚训练sigma矫正模型的时候使用了错误的NN模型结果,导致不得不花费多余的40分钟重新训练。如果没有那么多失误的话,恐怕能够选择最好的pipline。深切感受到“越着急的时候越容易出错”。
但我认为我们队伍合并的时间非常完美,让我们充分的利用了时间合并我们的方法,并进行了充分的探索和讨论。方法的契合度也非常的好,互相互补了薄弱的部分。虽然实际上以我的视点来说,我们的方法略有一些臃肿和不够优雅,但总的来说还是非常完美的。
正如takaitoさん的博客所写的,我们在完成最终提交后无所事事,因此干脆开始写solution,所以在第二天我们变成了第一个公布解决方案的队伍。非常有趣。
最后仔细想想,这次我几乎全程都维持在金段,说实话感到非常的不容易。
就结果来说,得到自己的第一块金牌还是非常的高兴的!但这不是我一个人力量能到达的位置,之后我想目指solo金牌和GM。
如果ADC2026还是有的话,我一定会参加。
各位辛苦了。
Reference
[1] Kai Hou Yip, Lorenzo V. Mugnai, Rebecca L. Coates, Andrea Bocchieri, Orphée Faucoz, Arun Nambiyath Govindan, Giuseppe Morello, Andreas Papageorgiou, Angèle Syty, Tara Tahseen, Sohier Dane, Maggie Demkin, Jean-Philippe Beaulieu, Sudeshna Boro Saikia, Giovanni Bruno, Quentin Changeat, Camilla Danielski, Pascale Danto, Jack Davey, Pierre Drossart, Paul Eccleston, Billy Edwards, Clare Jenner, Ryan King, Theresa Lueftinger, Michiel Min, Nikolaos Nikolaou, Leonardo Pagliaro, Enzo Pascale, Emilie Panek, Alice Radcliffe, Luís F. Simões, Patricio Cubillos Vallejos, Tiziano Zingales, Giovanna Tinetti, Ingo P. Waldmann. NeurIPS - Ariel Data Challenge 2025. https://kaggle.com/competitions/ariel-data-challenge-2025, Unpublished. Kaggle. . NeurIPS - Ariel Data Challenge 2025. https://kaggle.com/competitions/ariel-data-challenge-2025, 2025. Kaggle.
[2] Light Curve of a Planet Transiting Its Star https://science.nasa.gov/resource/light-curve-of-a-planet-transiting-its-star/